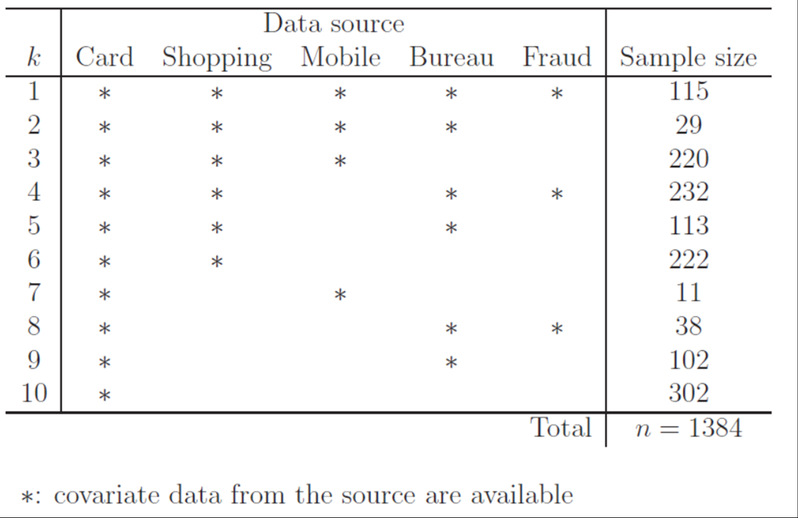
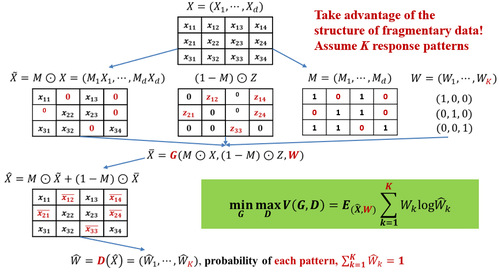
在审和在改的
[1] Geometric model averaging.
[2] High-dimensional factor augmented quantile regression: estimation, inference and simultaneous testing.
[3] Optimal linear combination of biomarkers by weighted Youden index maximization.
[4] Weighted stochastic gradient descent for linear models with large-scale fragmentary data.
[5] Integrated generalizd moment method with adaptive moment selection from external heterogeneous populations.
[6] Kolmogorov-Smirnov learning by neuron networks with a nonconvex surrogate loss.
会议论文
[1] Fang, Fang,Zhang, Riquan, and Zhao, Xinbin*. An aggregated evaluation and multi-dimensional comparison method of flight safety based on QAR data. IEEE - ICCASIT 2020.
期刊论文
[35] Zhong, Yan*#, Liu, Tong#, Fang, Fang#, Ge, Jia, Xu, Bohao, Zhao, Xinbin. Hard landing pattern recognition and precaution with QAR data by functional data analysis. IEEE Transactions on Aerospace and Electronic Systems, 2024, 60(4), 5101-5113.
[34] Lin, Xiefang and Fang, Fang*. Variable selection of Kolmogorov-Smirnov maximization with a penalized surrogate loss. Computational Statistics & Data Analysis, 2024, 195, Article 107944.
[33] Fang, Fang* and Bao, Shenliao. FragmGAN: Generative adversarial nets for fragmentary data imputation and prediction. Statistical Theory and Related Fields, 2024, 8(1), 15-28. An invited paper for special issue of causal inference, missing data and data integration.
[32] Yuan, Chaoxia, Fang, Fang*, and Li, Jialiang. Model averaging for generalized linear models in diverging model spaces with effective model size. Econometric Reviews, 2024, 43(1), 71-96.
[31] Fang, Fang*, Yuan, Chaoxia, and Tian, Wenling. An asymptotic theory for least squares model averaging with nested models. Econometric Theory, 2023, 39(2), 412-441.
[30] Yuan, Chaoxia*, Wu, Yang, and Fang Fang. Model averaging for generalized linear models in fragmentary data prediction. Statistical Theory and Related Fields, 2022, 6(4), 344-352.
[29] Fang Fang* , Yang, Qiwei, and Tian, Wenling. Cross-validation for selecting the penalty factor in least squares model averaging. Economics Letters, 2022, 217, Article 110683.
[28] Fang, Fang*, Li, Jialiang, and Xia, Xiaochao. Semiparametric model averaging prediction for dichotomous response. Journal of Econometrics, 2022, 229, 219-245.
[27] Yuan, Chaoxia, Fang, Fang, and Lyu Ni*. Mallows model averaging with effective model size in fragmentary data prediction. Computational Statistics & Data Analysis, 2022, 173, Article 107497.
[26] Fang, Fang, Zhao, jiwei, Ahmed, Ejaz, and Qu Annie*. A weak-signal-assisted procedure for variable selection and statistical inference with an informative subsample. Biometrics, 2021, 77, 996-1010.
[25] Chen, Ji, Shao, Jun, and Fang, Fang*. Instrument search in pseudo likelihood approach for nonignorable nonresponse. Annals of the Insititute of Statistical Mathematics, 2021, 73, 519-533.
[24] Wang, Lei, Shao, Jun, and Fang, Fang*. Propensity model selection with nonignorable nonresponse and instrument variable. Statistica Sinica, 2021, 31, 647-672.
[23] Fang, Fang* and Liu, Minhan. Limit of the optimal weight in least squares model averaging with non-nested models. Economics Letters, 2020, 196, 109586.
[22] Fang, Fang and Yu, Zhou*. Model averaging assisted sufficient dimension reduction. Computational Statistics & Data Analysis, 2020, 152, Article 106993.
[21] Ni, Lyu, Fang, Fang*, and Shao, Jun. Feature screening for ultrahigh dimensional categorical data with covariates missing at random. Computational Statistics & Data Analysis, 2020, 142, Article 106824.
[20] Fang, Fang*, Lan, Wei, Tong, Jingjing, and Shao, Jun. Model averaging for prediction with fragmentary data. Journal of Business & Economic Statistics. 2019, 37, 517-527
[19] Fang, Fang, Li, Jialiang* and Wang, Jingli. Optimal model averaging estimation for correlation structure in generalized estimating equations. Communications in Statistics - Simulation and Computation. 2019, 48, 1574-1593.
[18] Chen, Ji and Fang, Fang*. Semiparametric likelihood for estimating equations with nonignorable nonresponse by nonresponse instrument. Journal of Nonparametric Statistics. 2019, 31, 420-434.
[17] Fang, Fang* and Chen, Yuanyuan. A new approach for credit scoring by directly maximizing the Kolmogorov-Smirnov statistic. Computational Statistics & Data Analysis. 2019, 133, 180-194.
[16] Fang, Fang*, Yin, Xiangju, and Zhang, Qiang. Divide and conquer algorithms for model averaging with massive data. Journal of System Science and Mathematical Sciences, Chinese Series. 2018, 38, 764-776. An invited paper for the special issue of model averaging.
[15] Fang, Fang*, and Ni, Lyu. Variable screening with missing covariates: A discussion of Statistical inference for nonignorable missing data problems: A selective review by Niansheng Tang and Yuanyuan Ju. Statistical Theory and Related Fields, 2018, 2, 134-136.
[14] Fang, Fang, Zhao, Jiwei, and Shao, Jun*. Imputation-based adjusted score equations in generalized linear models with nonignorable missing covariate values. Statistica Sinica, 2018, 28, 1677-1701.
[13] Chen, Ji, Fang, Fang and Xiao, Zhiguo*, Semiparametric inference for estimating equations with nonignorable missing covaraites. Journal of Nonparametric Statistics, 2018, 30, 796-812.
[12] Ni, Lyu, Fang, Fang*, and Wan, Fangjiao. Adjusted Pearson Chi-Square feature screening for multi-classification with ultrahigh dimensional data. Metrika, 2017, 80, 805-828.
[11] Fang, Fang, and Shao, Jun*. Model selection with nonignorable nonresponse. Biometrika, 2016, 103, 861-874.
[10] Fang, Fang*, Fan, Xiaoyin, and Zhang Ying. Estimation of response from longitudinal binary data with noignorable missing values in migraine trails. Contemporary Clinical Trials Communications, 2016, 4, 90-98.
[9] Fang, Fang, and Shao, Jun*. Iterated imputation estimation for generalized linear models with missing response and covariate values. Computational Statistics & Data Analysis, 2016, 103, 111-123.
[8] Ni, Lyu, and Fang, Fang*. Entropy based model free feature screening for ultrahigh dimenisonal multiclass classification. Journal of Nonparametric Statistics, 2016, 28, 515-530.
[7] Fang, Fang*. Regression analysis with nonignorably missing covariates using surrogate data. Statistics and Its Interface, 2016, 9, 123-130.
[6] Fang, Fang, Hong, Quan, and Shao, Jun*. Empirical likelihood estimation for samples with nonignorable nonresponse. Statistica Sinica, 2010, 20, 263-280.
[5] Fang, Fang, Hong, Quan, and Shao, Jun*. A pseudo empirical likelihood approach for stratified samples with nonresponse. The Annals of Statistics, 2009, 37, 371-393 .
[4] 方方,资本项目开放与银行业务发展机遇探析,上海金融, 2013, No. 1, 98-101.
[3] 李麟、蒋波、方方,商业银行综合经营的边界、收益和风险,金融理论与实践, 2012, 396(7), 13-18.
[2] 李麟、方方、李晓玮,利率市场化下的区域商业银行转型,中国金融, 2012, No. 19, 70-72.
[1] 方方,“大数据”趋势下商业银行应对策略研究,新金融,2012, 286(12), 25-28.
其它文章:
[1] Fang, Fang and Lou, Zhilan. A Conversation with Jun Shao. ICSA Bulletin, 2015, 27, 69-77.
著作:
[3] 《多源数据的统计分析与建模》,方方,倪葎,邵军 著,上海交通大学出版社,2024。
[2] 《统计王国奇遇记》,方方 著,华东师范大学出版社,2020。
[1] 《中国银行业海外发展战略研究》,中国银行业协会发展研究委员会编著。参与编写。
授权专利:
[6] 一种广布种分布范围的预测方法,专利号:ZL 2020 1 0688315.5,授权日期:2023年10月24日。5/12。
[5] 一种计及记录偏差的航空数据匹配方法, 专利号:ZL 202211505325.6,授权日期:2023年7月21日。3/5。
[4] 一种两栖动物的探测率、占域率以及密度估算方法,专利号:ZL 2020 1 0747266.8,授权日期:2023年7月4日。9/9。
[3] 一种航空风险评价方法、装置及计算机设备,专利号:ZL 202010399853.2,授权日期:2023年6月13日。1/6。
[2] 一种运行风险量化方法、运行风险评价方法及装置,专利号:ZL 201811238049.5,授权日期:2023年5月23日。8/12。
[1] 一种鸟类密度估算方法,专利号:ZL202010671298.4,授权日期:2022年3月22日。8/9。